모니터링 메트릭 활용
메트릭 등록 - 예제 만들기
서비스 비즈니스에 특화된 부분을 모니터링 하기 위해서는 메트릭을 직접 등록하고 확인해야 한다.
서비스 중 주문수, 취소수, 재고 수량 같은 메트릭은 공통된 부분이 아닌 각각 비즈니스에 특화된 부분이다.
시스템 운영중 취소수가 갑자기 증가하거나 재고 수량이 임계치 이상으로 쌓이는 부분들은 CPU나 메모리 사용량 같은 시스템의 문제가 아니기 때문에 기술적인 메트릭으로 확인할 수 없다.
이럴 때 비즈니스 메트릭이 있으면 자사 시스템의 문제를 빠르게 파악하는데 도움을 준다.
예제로 만들 메트릭
- 주문수, 취소수
- 상품을 주문하면 주문수가 증가한다.
- 상품을 취소해도 주문수는 유지한다. 대신에 취소수를 증가한다.
- 재고 수량
- 상품을 주문하면 재고 수량이 감소한다.
- 상품을 취소하면 재고 수량이 증가한다.
- 재고 물량이 들어오면 재고 수량이 증가한다.
주문수, 취소수는 계속 증가하므로 카운터 사용.
재고 수량은 증가하거나 감소하므로 게이지 사용.
OrderService
주문, 취소, 재고 수량을 확인할 수 있는 주문 서비스 인터페이스

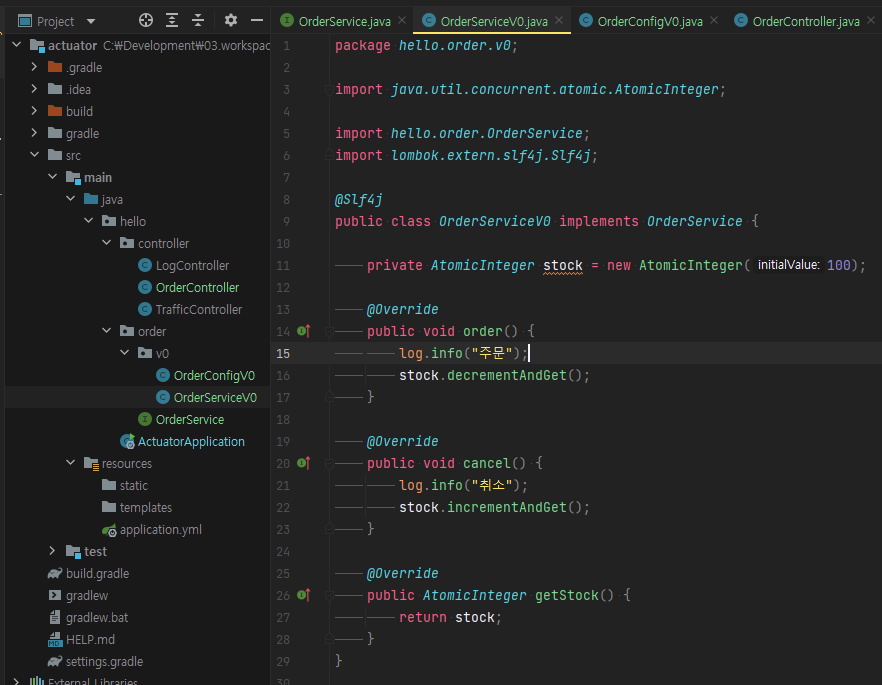
OrderServiceV0
OrderService를 구현한 구현체로 실제 비즈니스 로직이 들어간다.
재고수량 초기값은 100으로 설정.
OrderConfigV0
OrderServiceV0 빈을 직접 등록하는 설정

OderController
주문, 취소, 재고 수량을 확인하는 컨트롤러

ActuatorApplication

- @Import(OrderConfigV0.calss) : OrderServiceV0를 사용하는 설정
- @SpringBootApplication(scanBasePackages = "hello.controller") : 컴포넌트 스캔 대상을 컨트롤러로 제한. 이후에 추가할 OrderConfigVX가 모두 스프링 빈으로 등록되게 하지 않기 위한 설정
AtomicInteger
멀티스레드 환경에서 안전하게 값을 증가시키거나 감소시킬 수 있는 Integer.
즉 원자성을 보장하는 Integer이다. 멀티 쓰레드 환경에서 동기화 문제를 synchronized 키워드 없이 해결하기 위해 고안된 방법. synchronized의 특정 Thread가 해당 블락 전체를 lock 하기 때문에 다른 Thread는 아무 작업을 못하고 기다리는 상황이 되어 NonBlocking 하면서 동기화 문제를 해결하기 위한 방법이 Atomic이다. AtomicInteger의 동작 원리의 핵심은 CAS (Compare and Swap) 알고리즘에 있다.

멀티 쓰레드 환경, 멀티 코어 환경에서 각 CPU는 메인 메모리에서 변수값을 참조하는게 아닌 각 CPU의 캐시 영역에서 메모리 값을 참조한다. 이때, 메인 메모리에 저장된 값과 CPU 캐시에 저장된 값이 다른 경우가 있는데 이를 가시성 문제라고 한다. 이 때 사용되는 것이 CAS 알고리즘으로 현재 쓰레드에 저장된 값과 메인 메모리에 저장된 값을 비교하여 일치하는 경우 새로운 값으로 교체하고, 일치하지 않는다면 실패하고 재시도를 한다.
이렇게 처리되면 CPU 캐시에서 잘못된 값을 참조하는 가시성 문제가 해결되게 된다.
synchronized 블락의 경우 synchronized 블락 진입 전 후에 메인 메모리와 CPU 캐시 메모리값을 동기화하여 문제가 없도록 처리한다.
https://javaplant.tistory.com/23
AtomicInterger 완전정복 - CAS알고리즘(compareAndSet)
AtomicInteger 란?AtomicInteger란 원자성을 보장하는 Interger를 의미한다. 멀티 쓰레드 환경에서 동기화 문제를 별도의 synchronized 키워드 없이 해결하기 위해서 고안된 방법이다. (일반적으로 동기화 문
javaplant.tistory.com
실행



메트릭 등록1 - 카운터
마이크로미터를 사용해서 메트릭을 직접 등록해본다.
먼저 주문수, 취소수를 대상으로 카운터 메트릭을 등록
MeterRegistry
마이크로미터 기능을 제공하는 핵심 컴포넌트
스프링을 통해서 주입 받아 사용하고, 이곳을 통해서 카운터, 게이지 등을 등록한다.
Counter
- https://prometheus.io/docs/concepts/metric_types/#counter
- 단조롭게 증가하는 단일 누적 측정 항목
- 단일 값
- 보통 하나씩 증가
- 누적이므로 전체 값을 포함(total)
- 프로메테우스에서는 일반적으로 카운터의 이름 마지막에 _total을 붙여서 my_order_total과 같이 표현함
- 값을 증가하거나 0으로 초기화 하는 것만 가능
- 마이크로미터에서 값을 감소하는 기능도 지원하지만, 목적에 맞지 않음
- 예) HTTP 요청수
OrderServiceV1
주문수, 취소수 서비스에 카운터 메트릭 적용

- Counter.builder(name) 를 통해서 카운터를 생성한다. name 에는 메트릭 이름을 지정한다.
- tag를 사용했는데, 프로메테우스에서 필터를 할 수 있는 레이블로 사용된다.
- 주문과 취소는 메트릭 이름은 같고 tag를 통해서 구분하도록 했다.
- register(registry) : 만든 카운터를 MeterRegistry에 등록한다. 이렇게 등록해야 실제 동작한다.
- increment() : 카운터의 값을 하나 증가한다.
각각의 메서드를 호출할 때 마다 카운터가 증가한다.
OrderConfigV1
OrderServiceV1 빈을 직접 등록하는 설정

ActuatorApplication 변경

OrderConfigV0 -> OrderConfigV1 변경
실행


액츄에이터 메트릭 확인



- 메트릭을 확인해보면 method로 구분할 수 있다.
- 최소 한번 이상 호출해야 메트릭을 확인할 수 있다.
프로메테우스 포멧 메트릭 확인
http://localhost:8080/actuator/prometheus

- 메트릭 이름이 my.orer -> my_order_total로 변경된 것을 확인할 수 있다.
- 프로메테우스는 . -> _ 로 변경한다.
- 프로메테우스는 관례상 카운터 이름 끝에 _total을 붙인다
- method라는 tag, 레이블을 기준으로 데이터가 분류되어 있다.
그라파나 등록 - 주문수, 취소수
hello dashboard에 주문수, 취소수 그래프를 추가
- Add panel 버튼 선택
- Add a new panel 메뉴 선택
- Title : 주문수
- PromQL에 주문수 확인하는 메트릭 추가
- increase(my_order_total{method="order"}[1m])
- Legend : {{method}} : 메소드 이름으로 표시
- increase(my_order_total{method="cancel"}[1m])
- Legend : {{method}} : 메소드 이름으로 표시
- increase(my_order_total{method="order"}[1m])
카운터는 계속 증가하기 때문에 특정 시간에 얼마나 증가했는지 확인하려면 increase(), rate() 같은 함수와 함께 사용하는 것이 좋다.


메트릭 등록2 - @Counted
앞서만든 OrderServiceV1의 가장 큰 단점은 메트릭을 관리하는 로직이 핵심 비지니스 개발 로직에 침투했다는 점이다.

이러한 부분을 분리하려면 스프링 AOP를 사용하여 만들면 되지만, 마이크로미터는 이런 상황에 맞추어 필요한 AOP 구성요소를 만들어두었다.
OrderServiceV2

- @Counted 애노테이션을 측정을 원하는 메서드에 적용한다. 주문과 취소 메서드에 적용했다.
- 그리고 메트릭 이름을 지정하면 된다. 이전과 같은 my.order를 적용했다.
- 참고로 이렇게 사용하면 tag에 method를 기준으로 분류해서 적용한다.
OrderConfigV2

- CountedAspect를 등록하면 @Counted를 인지해서 Counter를 사용하는 AOP를 적용한다.
- CountedAspect를 빈으로 등록하지 않으면 @Counted 관련 AOP가 동작하지 않는다.
ActuatorApplication 변경

OrderConfigV1 -> OrderConfigV2 변경
실행


액츄에이터 메트릭 확인


- @Counted를 사용하면 result, exception, method, class 같은 다양한 tag를 자동으로 적용한다.
프로메테우스 포멧 메트릭 확인

그라파나 대시보드 확인
메트릭 이름과 tag가 기존과 같으므로 같은 대시보드에서 확인할 수 있다.

메트릭 등록3 - Timer
Timer
Timer는 특별한 메트릭 측정도구로 시간을 측정하는데 사용된다.
- 카운터와 유사한데, Timer를 사용하면 실행 시간도 함께 측정할 수 있다.
- Timer는 다음과 같은 내용을 한번에 측정해준다.
- seconds_count : 누적 실행수 - 카운터
- seconds_sum : 실행 시간의 합 - sum
- seconds_max : 최대 실행 시간(가장 오래걸린 실행 시간) - 게이지
- 내부에 타임 윈도우라는 개념이 있어서 1~3분 마다 최대 실행 시간이 다시 계산된다.
OrderServiceV3


- Timer.builder(name)을 통해서 타이머를 생성한다. name에는 메트릭 이름을 지정한다.
- tag를 사용했는데, 프로메테우스에서 필터할 수 있는 레이블로 사용된다.
- 주문과 취소는 메트릭 이름은 같고 tag를 통해서 구분하도록 했다.
- register(registry) : 만든 타이머를 MeterRegistry에 등록한다. 이렇게 등록해야 실제 동작한다.
- 타이머를 사용할 때는 timer.record()를 사용하면 된다. 그 안에 시간을 측정할 내용을 함수로 포함하면 된다.
걸리는 시간을 확인하기 위해 주문은 0.5초, 취소는 0.2초 대기하도록 했다. 추가로 가장 오래 걸린 시간을 확인하기 위해 sleep()에서 최대 0.2초를 랜덤하게 더 추가했다.(모두 0.5초로 같으면 가장 오래걸린 시간을 확인하기 어렵다.)
OrderConfigV3

ActuatorApplication - 변경

- OrderConfigV2 -> OrderConfigV3 변경
실행


액츄에이터 메트릭 확인

- measurements 항목을 보면 COUNT, TOTAL_TOME, MAX 이렇게 총 3가지 측정 항목을 확인할 수 있다.
- COUNT : 누적 실행 수(카운터와 같다)
- TOTAL_TIME : 실행 시간의 합(각각의 실행 시간의 누적 합)
- MAX : 최대 실행 시간(가장 오래 걸린 실행시간)
타이머를 사용하면 총 3가지 측정 항목이 생기는 것을 확인할 수 있다.
프로메테우스 포멧 메트릭 확인

프로메테우스로 다음 접두사가 붙으면서 3가지 메트릭을 제공한다.
- seconds_count : 누적 실행 수
- seconds_sum : 실행 시간의 합
- seconds_max : 최대 실행 시간(가장 오래걸린 실행 시간), 프로메테우스 gague
- 참고 : 내부에 타임 윈도우라는 개념이 있어서 1~3분 마다 최대 실행 시간이 다시 계산된다.
여기서 평균 실행 시간도 계산할 수 있다.
- seconds_sum / seconds_count = 평균 실행 시간
그라파나 등록 - 주문수 v3
hello dashboard에 주문수, 취소수 그래프를 추가 기존 패널은 이름이 변경되어 못 쓴다.
- Add panel 버튼 선택
- Add a new panel 메뉴 선택
- Title : 주문수 v3
- PromQL에 주문수 확인하는 메트릭 추가
- increase(my_order_seconds_count{method="order"}[1m])
- Legend : {{method}} : 메소드 이름으로 표시
- increase(my_order_seconds_count{method="cancel"}[1m])
- Legend : {{method}} : 메소드 이름으로 표시
- increase(my_order_seconds_count{method="order"}[1m])
참고 : 카운터는 계속 증가하기 때문에 특정 시간에 얼마나 증가했는지 확인하려면 increase(), rate() 같은 함수와 함께 사용하는 것이 좋다.


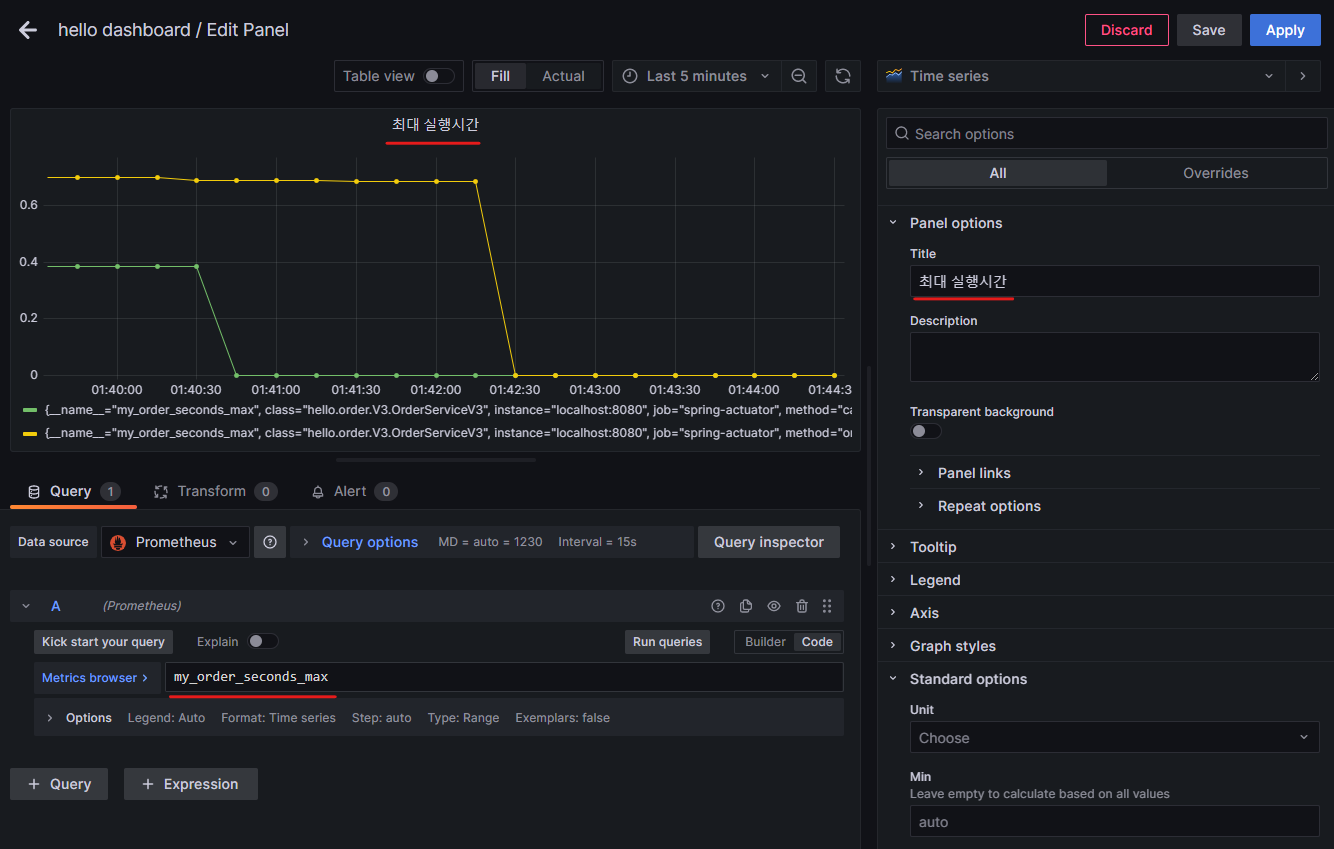
그라파나 등록 - 최대 실행시간
- Add panel 버튼 선택
- Add a new panel 메뉴 선택
- Title : 최대 실행시간
- PromQL에 주문수 확인하는 메트릭 추가
- my_order_seconds_max
그라파나 등록 - 평균 실행시간
- Add panel 버튼 선택
- Add a new panel 메뉴 선택
- Title : 평균 실행시간
- PromQL에 주문수 확인하는 메트릭 추가
- increase(my_order_seconds_sum[1m]) / increase(my_order_seconds_count[1m])

메트릭 등록4 - @Timed
타이머는 @Timed 라는 애노테이션을 통해 AOP를 적용할 수 있다.
OrderServiceV4


- @Timed("my.order")타입이나 메서드 중에 적용할 수 있다. 타입에 적용하면 해당 타입의 모든 public 메서드에 타이머가 적용된다. 참고로 이 경우 getStock()에도 타이머가 적용된다.
OrderConfigV4

- TimedAspect를 적용해야 @Timed에 AOP가 적용된다.
ActuatorApplication - 변경

OrderConfigV3 -> OrderConfigV4 변경
실행


액츄에이터 메트릭 확인

tag 중에 exception이 추가되는 부분을 제외하면 기존과 같다.
프로메테우스 포멧 메트릭 확인

생성되는 프로메테우스 포멧도 기존과 같다.
그라파나 대시보드 확인

메트릭 이름과 tag가 기존과 같으므로 같은 대시보드에서 확인할 수 있다.
메트릭 등록5 -게이지
Gauge(게이지)
- https://prometheus.io/docs/concepts/metric_types/#gauge
- 게이지는 임의로 오르내릴 수 있는 단일 숫자 값을 나타내는 메트릭
- 값의 현재 상태를 보는데 사용
- 값이 증가하거나 감소할 수 있음
- 예) 차량의 속도, CPU 사용량, 메모리 사용량
참고: 카운터와 게이지를 구분할 때는 값이 감소할 수 있는가를 고민해보면 도움이 된다.
재고 수량을 통해 게이지를 등록하는 방법 중 가장 단순한 방법
StockConfigV1

my.stock이라는 이름으로 게이지를 등록했다.
게이지를 만들 때 함수를 전달했는데, 이 함수는 외부에서 메트릭을 확인할 때마다 호출된다.
이 함수의 반환 값이 게이지의 값이다
@PostConstruct란?
종속성 주입이 완료된 후 실행되어야 하는 메서드에 사용된다. 이 어노테이션은 다른 리소스에서 호출되지 않아도 수행된다.
@PostConstruct의 사용 이유
1) 생성자가 호출되었을 때, 빈은 초기화되지 않았음(의존성 주입이 이루어지지 않았음)
이럴 때 @PostConstruct를 사용하면 의존성 주입이 끝나고 실행됨이 보장되므로 빈의 초기화에 대해서 걱정할 필요가 없다.
2) bean 의 생애주기에서 오직 한 번만 수행된다는 것을 보장한다. (어플리케이션이 실행될 때 한번만 실행됨)
따라서 bean이 여러 번 초기화되는 걸 방지할 수 있다.
https://superbono-2020.tistory.com/186
ActuatorApplication - 변경
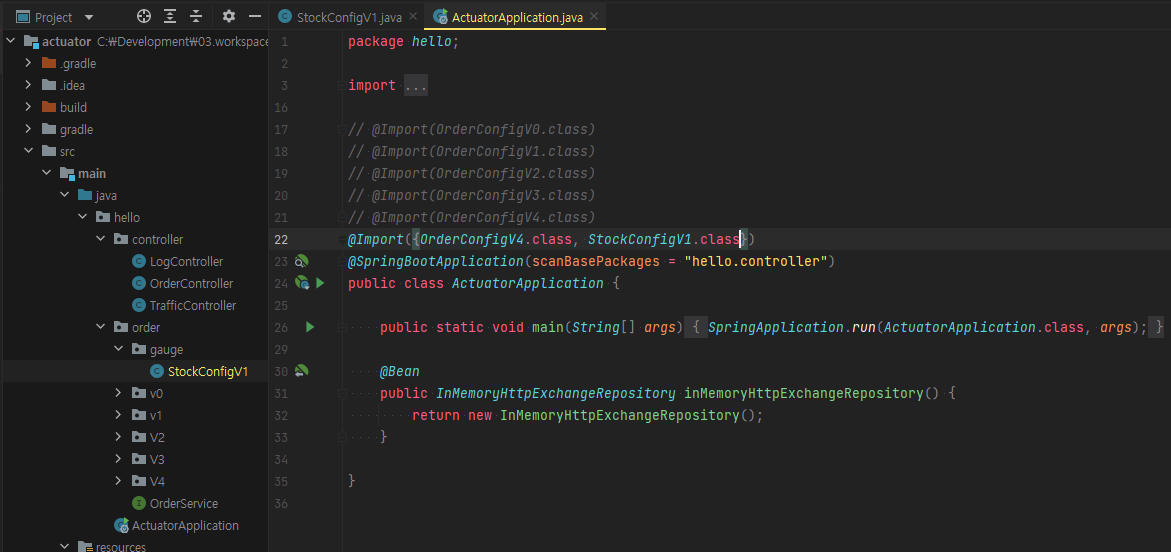
OrderConfigV4 -> @Import({OrderConfigV4.class, StockConfigV1.class})로 변경

애플리케이션을 실행하면 stock gauge call 로그가 주기적으로 남는 것을 확인할 수 있다.
게이지를 확인하는 함수는 외부에서 메트릭을 확인할 때 호출 된다. 현재 프로메테우스가 다음 경로를 통해 주기적으로 메트릭을 확인하기 때문이다.
http://localhost:8080/actuator/prometheus
프로메테우스를 종료하면 해당 함수는 호출되지 않는다. 프로메테우가 종료되었어도 메트릭 확인 경로를 직접 호출하면 해당 함수가 호출된다.
카운터와 다르게 게이지는 무언가 누적할 필요도 없고, 딱 현재 시점의 값을 보여주면 된다. 따라서 측정시점에 현재 값을 반환한다.
액츄에이터 메트릭 확인

게이지는 현재 값을 그대로 보여주면 되므로 단순하다.
프로메테우스 포멧 메트릭확인

그라파나 등록 - 재고
- Add panel 버튼 선택
- Add a new panel 메뉴 선택
- Title : 재고
- PromQL에 재고 확인하는 메트릭 추가
- my_stock

게이지 단순하게 등록하기
StockConfigV2

MeterBinder 타입을 바로 반환해도 된다. ??
ActuatorApplication - 변경

StockConfigV1 -> @Import({OrderConfigV4.class, StockConfigV2.class})로 변경
그라파나 대시보드 확인

메트릭 이름이 기존과 같으므로 같은 대시보드에서 확인할 수 있다.
실무 모니터링 환경 구성 팁
모니터링 3단계
- 대시보드
- 애플리케이션 추적 - 핀포인트
- 로그
대시보드
전체를 한눈에 볼 수 있는 가장 높은 뷰
제품
마이크로미터, 프로메테우스, 그라파나 등등
모니터링 대상
시스템 메트릭(CPU, 메모리)
애플리케이션 메트릭(톰캣 쓰레드 풀, DB 커넥션 풀, 애플리케이션 호출 수)
비즈니스 메트릭(주문수, 취소수)
애플리케이션 추적
주로 각각의 HTTP 요청을 추적, 일부는 마이크로서비스 환경에서 분산 추적
제품
핀포인트(오픈소스), 스카우트(오픈소스), 와탭(상용), 제니퍼(상용)
https://github.com/pinpoint-apm/pinpoint
GitHub - pinpoint-apm/pinpoint: APM, (Application Performance Management) tool for large-scale distributed systems.
APM, (Application Performance Management) tool for large-scale distributed systems. - GitHub - pinpoint-apm/pinpoint: APM, (Application Performance Management) tool for large-scale distributed sys...
github.com
로그
가장 자세한 추적, 원하는데로 커스텀 가능
같은 HTTP 요청을 묶어서 확인할 수 있는 방법이 중요, MDC 적용
파일로 직접 로그를 남기는 경우
일반 로그와 에러 로그는 파일을 구분해서 남기자
에러 로그만 확인해서 문제를 바로 정리할 수 있음
클라우드에 로그를 저장하는 경우
검색이 잘 되도록 구분
모니터링 정리
각각 용도가 다르다.
관찰을 할 때는 전체 -> 점점 좁게
핀포인트는 정말 좋다. 강추 마이크로 서비스 분산 모니터링도 가능, 대용량 트래픽에 대응
알람
모니터링 툴에서 일정 이상 수치가 넘어가면, 슬랙, 문자 등을 연동
알람은 2가지 종류로 꼭 구분해서 관리
경고, 심각
경고는 하루에 1번정도 사람이 확인해도 되는 수준(사람이 들어가서 확인)
심각은 즉시 확인해야함, 슬랙 알림(앱을 통해 알림 받도록), 문자, 전화
예)
- 디스크사용량 70% -> 경고
- 디스크 사용량 80% -> 심각
- CPU 사용량 40% -> 경고
- CPU 사용량 50% -> 심각
경고와 심각을 잘 나누어서 업무와 삶에 방해가 되지 않도록 해야함.
거짓(False) 알림은 바로바로 처리